Selon JetBrains, JavaScript demeure le langage le plus utilisé en 2024
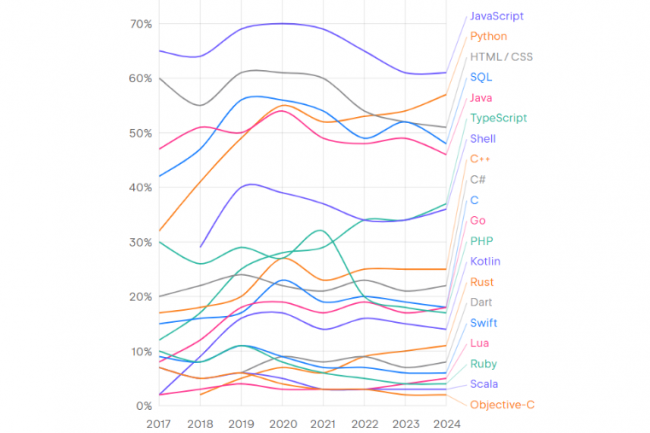
Selon le rapport State of Developer Ecosystem Report 2024 de JetBrains, JavaScript est encore le langage de programmation le plus utilisé. Mais TypeScript, Rust et Python présentent des perspectives de croissance les plus prometteuses. TypeScript, Rust et Python ont connu les plus fortes croissances d’adoption des langages de programmation en 2024. (crédit : JetBrains) Quels sont les langages de programmation les plus utilisés ? Depuis 7 ans JetBrains se penche sur la question et vient de livrer son palmarès 2024. Son dernier rapport révèle que JavaScript, avec 61 % des développeurs du monde entier qui l’utilisent pour créer des pages web, reste le langage de programmation le plus populaire au monde. Python arrive deuxième, avec 57 % des développeurs, suivi par HTML/CSS (51 %), SQL (48 %), Java (46 %) et TypeScript (37 %). Parmi ces langages, cependant, seuls Python et TypeScript ont vu leur usage progresser significativement sur un an (+3 points dans les deux cas). L’utilisation de C#, Go et Rust a également augmenté, selon le rapport, mais tous de 1 point sur la même période. Publiée le 11 décembre, cette huitième édition du rapport de JetBrains s’appuie sur les réponses de 23 262 développeurs du monde entier, interrogés entre mai et juin 2024. Pour mieux évaluer les perspectives de croissance des langages de programmation, l’étude introduit le Language Promise Index (LPI), qui se base sur la croissance de l’utilisation du langage au cours des cinq dernières années, la stabilité de cette croissance, la part des développeurs ayant l’intention d’adopter le langage, et la part des utilisateurs actuels du langage qui souhaitent en adopter un autre. Sur la base de cette formule, les « leaders incontestés » du LPI sont TypeScript, Rust et Python, a indiqué l’éditeur. Le recours à TypeScript est passé de 12 % en 2017 à 35 % en 2024, tandis que l’utilisation de Python est passée de 32 % en 2017 à 57 % en 2024 et celle de Rust a bondi de 2 % en 2018 à 11 % en 2024. L’usage de Java a quant à elle légèrement reculé (47 % en 2017 versus 46 % en 2024 alors qu’elle avait bondi à 54 % en 2020). Malgré ses gains, TypeScript ne remplacera pas JavaScript, selon le rapport. Ce dernier reste l’une des technologies les plus populaires et les plus fondamentales dans le secteur du développement logiciel. Néanmoins, TypeScript apporte des avantages par rapport à JavaScript, notamment la détection précoce des erreurs au cours du développement, l’amélioration de la qualité du code, la détection des erreurs au moment de la compilation, un remaniement plus fiable et la prise en charge native des modules ECMAScript 2015 (ES^). Codage dopé à l’IA : ChatGPT devance Github Copilot Go et Rust sont les langages que la plupart des personnes interrogées prévoient d’adopter. Aspirant à remplacer le C++ par des mécanismes stricts de sécurité et de propriété de la mémoire, Rust a vu sa base d’utilisateurs augmenter régulièrement au cours des cinq dernières années. ChatGPT est l’outil de codage d’IA le plus testé, avec 69 % des développeurs l’ayant essayé, suivi par GitHub Copilot à 40 %. Les États-Unis ont le salaire médian le plus élevé pour les développeurs, soit 144 000 $. La plupart des développeurs (38 %) déclarent que la compréhension des besoins des utilisateurs est la partie la plus difficile de leur travail, suivie par la communication avec d’autres fonctions (34 %) et le code (32 %). Les bases de données open source – MySQL, PostgreSQL, MongoDB, SQLite et Redis – dominent les options de stockage utilisées par les développeurs dans l’écosystème JetBrains. Enfin, Amazon Web Services reste de loin la plateforme cloud la plus utilisée (46% des répondants), suivie de Microsoft Azure (17%).
Read More